
Developer eXperience
Section "Developer experience" dans l'article wikipedia : https://en.wikipedia.org/wiki/User_experience#Developer_experience
Le terme "Developer Experience" (DX) fait référence à l'ensemble des perceptions, sentiments et interactions qu'un développeur éprouve lorsqu'il utilise des outils, des frameworks, des API, et des plateformes pour développer des logiciels.
Il s'agit d'une notion centrée sur l'utilisateur, similaire à l'expérience utilisateur (UX) mais spécifiquement orientée vers les développeurs. -- ChatGPT
Journaux liées à cette note :
gh-issue-sync: sync GitHub issues locally and back
gh-issue-sync is a command line tool that syncs GitHub issues to local Markdown files for offline editing, batch updates, and integration with coding agents.
Pull issues locally, refine them until you are satisfied, and sync changes back. Also useful for offline access to your issues.
C'est un outil qui répond à un besoin que j'ai depuis 2018 : préparer avec un process précis des issues GitLab ou GitHub en draft, dans un format texte versionnable, particulièrement utile pendant la phase de meta-spec-writing.
C'est pour répondre à ce besoin que j'avais spécifié les fonctionnalités suivantes dans Projet 24 - Prototyper le gestionnaire de projet de mes rêves :
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
Je trouve curieux de voir émerger des projets comme Beads en octobre 2025 ou gh-issue-sync en décembre 2025, portés par la mouvance Specs Driven Development des agents IA, alors que j'explore ce formalisme depuis environ 2010. Ce qui m'intrigue surtout : pourquoi les développeurs s'intéressent à la spécification maintenant, et pas avant ? J'ai commencé à rédiger des choses à ce sujet, que je souhaite publier.
Le 15 mars dernier, j'ai créé des commandes OpenCode issue-create.md, issue-pull.md, issue-push.md, issue-update.md dont l'objectif était plus ou moins identique à gh-issue-sync : rédiger une issue dans un fichier local, la raffiner, puis l'envoyer vers GitHub. J'ai utilisé ces commandes pour créer les issues du projet sklein-devbox : https://github.com/stephane-klein/sklein-devbox/issues.
En l'état, je ne suis pas satisfait de mon expérience de développeur (DX). Il me semble que la fonctionnalité SKILL.md de gh-issue-sync offre probablement une meilleure architecture que l'utilisation des commandes OpenCode.
Ces prochains jours, je compte tester gh-issue-sync pour un éventuel remplacement. À plus long terme, j'aimerais pousser plus loin le sujet en testant Beads.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Je fais mon retour dans l'écosystème React, j'ai découvert Jotai et Zustand
Dans le code source de mon projet professionnel, #JaiDécouvert la librairie ReactJS nommée Jotai (https://jotai.org).
Les atom de Jotai ressemblent aux fonctionnalités Svelte Store. Jotai permet entre autres d'éviter de faire du props drilling.
Pour en savoir plus sur l'intérêt de Jotai versus "React context (useContext + useState)", je vous conseille la lecture d'introduction de la page Comparison de la documentation Jotai. J'ai trouvé la section "Usage difference" très simple à comprendre.
Cette découverte est une bonne surprise pour moi, car les atom de Jotai reproduisent l'élégance syntaxique des Store de Svelte, ce qui améliore mon confort de développement en ReactJS. #JaiLu ce thread Hacker News en lien avec le sujet : "I like Svelte more than React (it's store management)".
Je tiens toutefois à préciser que si Jotai améliore significativement mon expérience de développeur (DX) avec ReactJS, cela reste une solution de gestion d'état au sein du runtime ReactJS. En comparaison, le compilateur Svelte génère du code optimisé natif qui reste intrinsèquement plus performant à l'exécution.
Exemple Svelte :
import { writable, derived } from 'svelte/store';
const count = writable(0);
const doubled = derived(count, $count => $count * 2);
// Usage dans component
$count // auto-subscription
Exemple ReactJS basé sur Jotai :
import { atom } from 'jotai';
const countAtom = atom(0);
const doubledAtom = atom(get => get(countAtom) * 2);
// Usage dans component
const [count] = useAtom(countAtom);
J'ai lu la page "Comparison" de Jotai pour mieux comprendre la place qu'a Jotai dans l'écosystème ReactJS.
#JaiDécouvert deux autres librairies développées par la même personne, Daishi Kato : Zustand et Valtio. D'après ce que j'ai compris, Daishi a développé ces librairies dans cet ordre :
- Zustand en juin 2019 - voir "How Zustand Was Born"
- La première version de Jotai en septembre 2020 - voir "How Jotai Was Born"
- La première version de Valtio en mars 2021 - voir "How Valtio Was Born"
J'ai aussi découvert Recoil développé par Facebook, mais d'après son entête GitHub celle-ci semble abandonnée. Une migration de Recoil vers Jotai semble être conseillée.
J'aime beaucoup comment Daishi Kato choisit le nom de ses librairies, la méthode est plutôt simple 🙂 :
Comme mentionné plus haut, Jotai ressemble à Recoil alors que Zustand ressemble à Redux :
Analogy
Jotai is like Recoil. Zustand is like Redux.
...
How to structure state
Jotai state consists of atoms (i.e. bottom-up). Zustand state is one object (i.e. top-down).
Même en lisant la documentation Comparison, j'ai eu de grandes difficulté à comprendre quand préférer Zustand à Jotai.
En lisant la documentation, Jotai me semble toujours plus simple à utiliser que Zustand.
Avec l'aide de Claude Sonnet 4.5, je pense avoir compris quand préférer Zustand à Jotai.
Exemple Zustand
Dans l'exemple Zustand suivant, la fonction addToCart modifie plusieurs parties du state useCartStore en une seule transaction :
import { create } from 'zustand'
const useCartStore = create((set) => ({
user: null,
cart: [],
notifications: [],
addToCart: (product) => set((state) => {
return {
cart: [...state.cart, product],
notifications: (
state.user
? [...state.notifications, { type: 'cart_updated' }]
: state.notifications
)
};
};
}));
Et voici un exemple d'utilisation de addToCart dans un composant :
function ProductCard({ product }) {
// Sélectionner uniquement l'action addToCart
const addToCart = useCartStore((state) => state.addToCart);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Exemple Jotai
Voici une implémentation équivalente basée sur Jotai :
import { atom } from 'jotai';
const userAtom = atom(null);
const cartAtom = atom([]);
const notificationsAtom = atom([]);
export const addToCartAtom = atom(
null,
(get, set, product) => {
const user = get(userAtom);
const cart = get(cartAtom);
const notifications = get(notificationsAtom);
set(cartAtom, [...cart, product]);
if (user) {
set(notificationsAtom, [...notifications, { type: 'cart_updated' }]);
}
}
);
Et voici un exemple d'utilisation de useToCartAtom dans un composant :
import { useSetAtom } from 'jotai';
import { addToCartAtom } from 'addToCartAtom';
function ProductCard({ product }) {
// Récupérer uniquement l'action (pas la valeur)
const addToCart = useSetAtom(addToCartAtom);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Ces deux exemples montrent que Zustand est plus élégant et probablement plus performant que Jotai pour gérer des actions qui conditionnent ou modifient plusieurs parties du state simultanément.
#JaiLu le thread SubReddit ReactJS "What do you use for global state management? " et j'ai remarqué que Zustand semble plutôt populaire.
En rédigeant cette note, j'ai découvert Valtio qui semble être une alternative à MobX. Je prévois d'étudier ces deux librairies dans une future note.
J'ai découvert la méthode officielle de SvelteKit pour accéder aux variables d'environnement
Voici une nouvelle fonctionnalité qui illustre pourquoi j'apprécie l'expérience développeur (DX) de SvelteKit : la simplicité d'accès aux variables d'environnement !
Je commence avec un peu de contexte.
Comme je l'ai déjà dit dans une précédente note, je suis depuis 2015 les principes de The Twelve-Factors App.
Concrètement, quand je déploie un frontend web qui a besoin de paramètres de configuration, par exemple une URL pour accéder à une API, je déploie quelque chose qui ressemble à ceci :
# docker-compose.yml
services:
webapp:
image: ...
environment:
GRAPHQL_API: https://example.com/
De 2012 à 2022, quand ma doctrine était de produire des frontend web en SPA, j'avais recours à du boilerplate code à base de commande sed dans un entrypoint.sh, qui avait pour fonction d'attribuer des valeurs aux variables de configuration — comme dans cet exemple GRAPHQL_API — au moment du lancement du container Docker, exemple : entreypoint.sh.
Ce système était peu élégant, difficile à expliquer et à maintenir.
Ce soir, j'ai découvert les fonctionnalités suivantes de SvelteKit :
J'ai publié ce playground sveltekit-environment-variable-playground qui m'a permis de tester ces fonctionnalités dans un projet SSR avec hydration.
J'ai testé comment accéder à trois variables dans trois contextes différents (.envrc) :
# Set at application build time
export PUBLIC_VERSION="0.1.0"
# Set at application startup time and accessible only on server side
export POSTGRESQL_URL="postgresql://myuser:mypassword123@localhost:5432/mydatabase"
# Set at application startup time and accessible on frontend side
export PUBLIC_GOATCOUNTER_ENDPOINT=https://example.com/count
Cela fonctionne parfaitement bien, c'est simple, pratique, un pur bonheur.
Pour plus de détails, je vous invite à regarder le playground et à tester par vous-même.
Merci aux développeurs de SvelteKit ❤️.
J'ai regardé ce que propose NextJS et je constate qu'il propose moins de fonctionnalités.
D'après ce que j'ai compris, NextJS propose l'équivalent de $env/dynamic/private et $env/static/public mais j'ai l'impression qu'il ne propose rien d'équivalent à $env/dynamic/public.
Bilan de poc-sveltekit-custom-server
Contexte et objectifs
Dans le projet gibbon-replay, j'ai besoin d'exécuter une tâche une fois par jour pour supprimer des anciennes sessions.
gibbon-replay utilise une base de données SQLite qui ne dispose pas nativement de fonctionnalité de type Time To Live, comme on peut trouver dans Clickhouse.
SQLite ne propose pas non plus d'équivalent à pg_cron — ce qui est tout à fait normal étant donnée que SQLite est une librairie et non pas un service à part entière.
Le projet gibbon-replay est un monolith (j'aime les monoliths !) et je souhaite conserver ce choix.
Face à ces contraintes, une solution consiste à intégrer une solution comme Cron for Node.js directement dans l'application gibbon-replay.
Je pense que je dois implémenter cela dans un SvelteKit Custom Server, ce qui me permettrait d'exécuter cette tâche de purge à intervalles réguliers tout en conservant l'architecture monolithique.
Il y a quelques jours, j'ai décidé de tester cette idée dans un POC nommé : poc-sveltekit-custom-server.
J'ai aussi décidé d'expérimenter un objectif supplémentaire dans ce POC : lancer la migration du modèle de données dès le lancement du monolith et non plus lors de la première requête HTTP reçue par le service.
Enfin, je souhaitais ne pas dégrader l'expérience développeur (DX), c'est à dire, je souhaitais pouvoir continuer à simplement utiliser :
$ pnpm run dev
ou
$ pnpm run build
$ pnpm run preview
sans différence avec un projet SvelteKit "vanilla".
Résultats du POC et enseignements
Tout d'abord, le POC fonctionne parfaitement 🙂, sans dégrader l'expérience développeur (DX), qui ressemble à ceci :
$ mise install
$ pnpm install
$ pnpm run load-seed-data
Start data model migration…
Data model migration completed
Start load seed data...
seed data loaded
Lancement du projet en mode développement :
$ pnpm run dev
Start data model migration…
Data model migration completed
Server started on http://localhost:5173 in development mode
Lancement du projet "buildé" :
$ pnpm run build
$ pnpm run preview
Start data model migration…
Data model migration completed
Server started on http://localhost:3000 in production mode
Les migrations et les données "seed.sql" se trouvent dans le dossier /sqls/.
Le SvelteKit Custom Server est implémenté dans le fichier src/server.js et il ressemble à ceci :
import express from 'express';
import cron from 'node-cron';
import db, { migrate } from '@lib/server/db.js';
const isDev = process.env.ENV !== 'production';
migrate(); // Lancement de la migration du modèle de donnée dès de lancement du serveur
// Configuration d'une tâche exécuté toutes les heures
cron.schedule(
'0 * * * *',
async () => {
console.log('Start task...');
console.log(db().query('SELECT * FROM posts'));
console.log('Task executed');
}
);
async function createServer() {
const app = express();
...
Personnellement, je trouve cela simple et minimaliste.
Point de difficulté
SvelteKit utilise des "module alias", comme par exemple $lib.
Problème, par défaut, ces "module alias" ne sont pas configurés lors de l'exécution de node src/server.js.
Pour me permettre d'importer dans src/server.js des modules de src/lib/server/* comme :
import db, { migrate } from '@lib/server/db.js';
j'ai utilisé la librairie esm-module-alias.
Ceci complexifie un peu le projet, j'ai dû configurer ceci dans /package.json :
{
"scripts": {
"dev": "ENV=development node --loader esm-module-alias/loader --no-warnings src/server.js",
"preview": "ENV=production node --loader esm-module-alias/loader --no-warnings build/server.js",
...
"aliases": {
"@lib": "src/lib/"
}
}
- ajout de
--loader esm-module-alias/loader --no-warnings - et la section
aliases
Et dans /vite.config.js :
export default defineConfig({
plugins: [sveltekit()],
resolve: {
alias: {
'@lib': path.resolve('./src/lib')
}
}
});
- ajout de
alias
Le fichier src/server.js contient du code spécifique en fonction de son contexte d'exécution ("dev" ou "buildé") :
if (isDev) {
const { createServer: createViteServer } = await import('vite');
const vite = await createViteServer({
server: { middlewareMode: true },
appType: 'custom'
});
app.use(vite.middlewares);
} else {
const { handler } = await import('./handler.js');
app.use(handler);
}
En mode "dev" il utilise Vite et en "buildé" il utilise le fichier build/handler.js généré par SvelteKit build en mode SSR.
Le fichier src/server.js est copié vers le dossier /build/ lors de l'exécution de pnpm run build.
J'ai testé le bon fonctionnement du POC dans un container Docker.
J'ai intégré au projet un deployment-playground : https://github.com/stephane-klein/poc-sveltekit-custom-server/tree/main/deployment-playground.
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Update du 2025-05-29 à 00:07 - Je viens de publier ceci :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/?
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Pourquoi faire un refactoring de Nuxt.js vers HTMX ? 🤔
En étudiant l'annonce Développeur(se) back-end en CDI de Brief.me j'ai été intrigué par :
Je me suis demandé quelle est la motivation de passer d'un framework de type Nuxt.js, NextJS ou SvelteKit à htmx 🤔.
J'utilise SvelteKit depuis deux ans, qui est comparable Nuxt.js, principalement en mode SSR avec Hydration, et je suis totalement satisfait. Ma Developer eXperience est excellente. Je trouve ce framework minimaliste, conforme au principe Keep it simple, stupid! (KISS), et performant.
Après réflexion, j'ai réalisé que mon expérience de développeur (DX) serait moindre si j'héritais d'un backend codé dans un langage autre que Javascript : Python, PHP, Ruby, Golang…
Et Brief.me semble être dans ce cas de figure :
- Back-end : Django, PostgreSQL, RabbitMQ, Celery
- Front-end : HTMX
- Tests : pytest
- Infra : Platform.sh
Je me suis connecté à mon compte Brief.me et en regardant ce que me retourne Wappalyzer, je constate que le site est effectivement propulsé par Nuxt.js, VueJS.
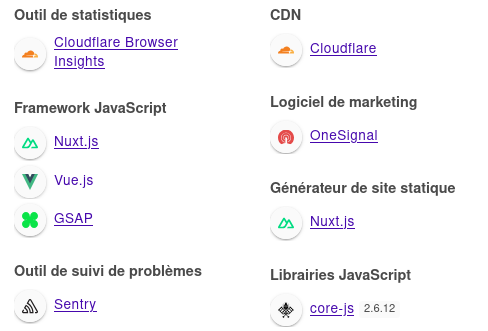

En regardant ce qu'il se passe dans l'onglet Réseau de mon navigateur, je constate que https://app.brief.me est un site web de type SPA. Le contenu des articles est chargé via l'api https://www.brief.me/api/ qui est propulsée par Django REST framework.
Si je résume, la stack est la suivante : PostgreSQL => Django => Django REST framework <=> Nuxt.js => Rendu HTML via VueJS.
Je suppose que ce qui motive la migration de Nuxt.js vers HTMX est la suppression de couches.
Plus précisément, je suppose que l'équipe tech de Brief.me souhaite supprimer les couches suivantes :
Et utiliser simplement le système de template de Django en SSR pour afficher le contenu des articles et implémenter les quelques éléments dynamiques côté browser avec HTMX.
De mon point de vue, ceci a pour avantage de largement simplifier la stack, de simplifier le déploiement et d'accélérer le chargement des pages.
Ma conclusion : la librairie HTMX semble être un choix très pertinent quand elle est utilisée dans une stack non NodeJS.
Journal du vendredi 04 octobre 2024 à 20:58
Je viens de mettre en œuvre better-sqlite3-helper ici dans le projet gibbon-replay, afin d'utiliser son système de migration de schemas.
L'expérience développeur (DX) est bonne, j'ai apprécié les fonctions helpers query, queryFirstRow, queryFirstCell, insert, etc.
Journal du dimanche 01 septembre 2024 à 10:42
Suite à des échanges avec Alexandre au sujet de la "position" et de l'usage de Ollama dans le domaine des LLM, j'ai pris un peu de temps pour essayer d'y voir plus clair.
#JaiLu ce thread Reddit : newbie confusion: LocalLM / AnythingLLM / llama.cpp / Lamafile / Ollama / openwebui All the same? : LocalLLM
Voici ma description d'Ollama. Ollama est un wrapper au-dessus de llama.cpp afin de rendre son utilisation davantage User Friendly. Ollama est écrit en Golang.
D'après :
Supported backends
- llama.cpp project founded by Georgi Gerganov
-- from
et la présence de llama.cpp directement dans le code source de Ollama
Je comprends que pour le moment, Ollama supporte uniquement le backend llama.cpp.
Conclusion : je pense qu'il est préférable d'utiliser Ollama plutôt que directement llama.cpp.
Journal du jeudi 29 août 2024 à 13:23
Voici les nouveautés depuis ma dernière itération du Projet 11 - "Première version d'un moteur web PKM".
Ce commit contient le résultat du travail du Projet 13, c'est-à-dire le refactoring de PostgreSQL vers Elasticsearch ainsi que la page /src/routes/search qui permet à la fois d'effectuer une recherche sur le contenu des notes et un filtrage de type and sur les tags.
Une démo est visible ici https://notes.develop.sklein.xyz/

Ma Developer eXperience avec Elasticsearch est excellente. J'ai trouvé toutes les fonctionnalités dont j'avais besoin.
Je pense que mon utilisation des Fleeting Note n'est pas la bonne. Je pense que les notes que je qualifie de Fleeting Note sont en réalité des Diary notes ou Journal notes.
J'ai donc décidé de :
- [x] Renommer partout
fleeting_noteenjournal_notes
Après implémentation, j'ai réalisé que j'ai fait l'erreur de mélanger l'implémentation de le page qui affiche la liste des notes antéchronologiques et la page de recherche.
Pour être efficace, le résultat de la page recherche doit être affiché en fonction du scoring de la recherche, alors que les pages listes de notes par date de publication.
J'ai donc décidé de :
- [x] Implémenter une page
/diaries/(pour la cohérence des path en anglais, je préfère "diaries" à "journaux") qui affiche une liste de notes de type Diary notes ;- [x] Cette page doit permettre un filtrage par tags
- [x] Implémenter une page
/notes/qui affiche une liste des notes qui ne sont pas de type Diary notes, comme des Evergreen Note, Hub note…- [x] Contrairement à la page liste des Diary notes, cette page de liste ne doit pas afficher le contenu des notes, mais seulement le titre des notes ;
- [x] Je propose de classer ces titres de notes par ordre alphabétique ;
- [x] Je propose aussi de séparer ces notes par lettre,
A,B… c'est-à-dire un index alphabétique. - [x] Cette page doit permettre un filtrage par tags
- [x] Refactoring la page
/search/pour ordonner le résultat de la recherche par scoring.- [x] Cette page doit afficher le contenu des notes avec highligthing ;
- [x] Cette page doit permettre un filtrage sur les types de notes, pour le moment Diary notes et Evergreen Note.
- [x] Cette page doit permettre un filtrage par tags
Au moment où j'écris ces lignes, je ne sais pas encore comment je vais gérer les opérateurs or, (.
Pour le moment, le filtrage multi tags est effectué avec des and.
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.